株式会社Quest Research(本社:東京都港区、代表取締役:南健太)は、生成AIを活用したインタビューサービス「qork(コルク)」において、大規模言語モデル(LLM)を活用した候補者自動フィルタリング機能をリリースしました。
本機能により、従来は人間が手作業で行っていた複雑なデータ整理とフィルター条件の設定作業が自動化され、インタビュー候補者の抽出精度と速度が大幅に向上しました。また、最大1000名規模の大規模候補者プールに対しても高速処理が可能です。
■機能概要
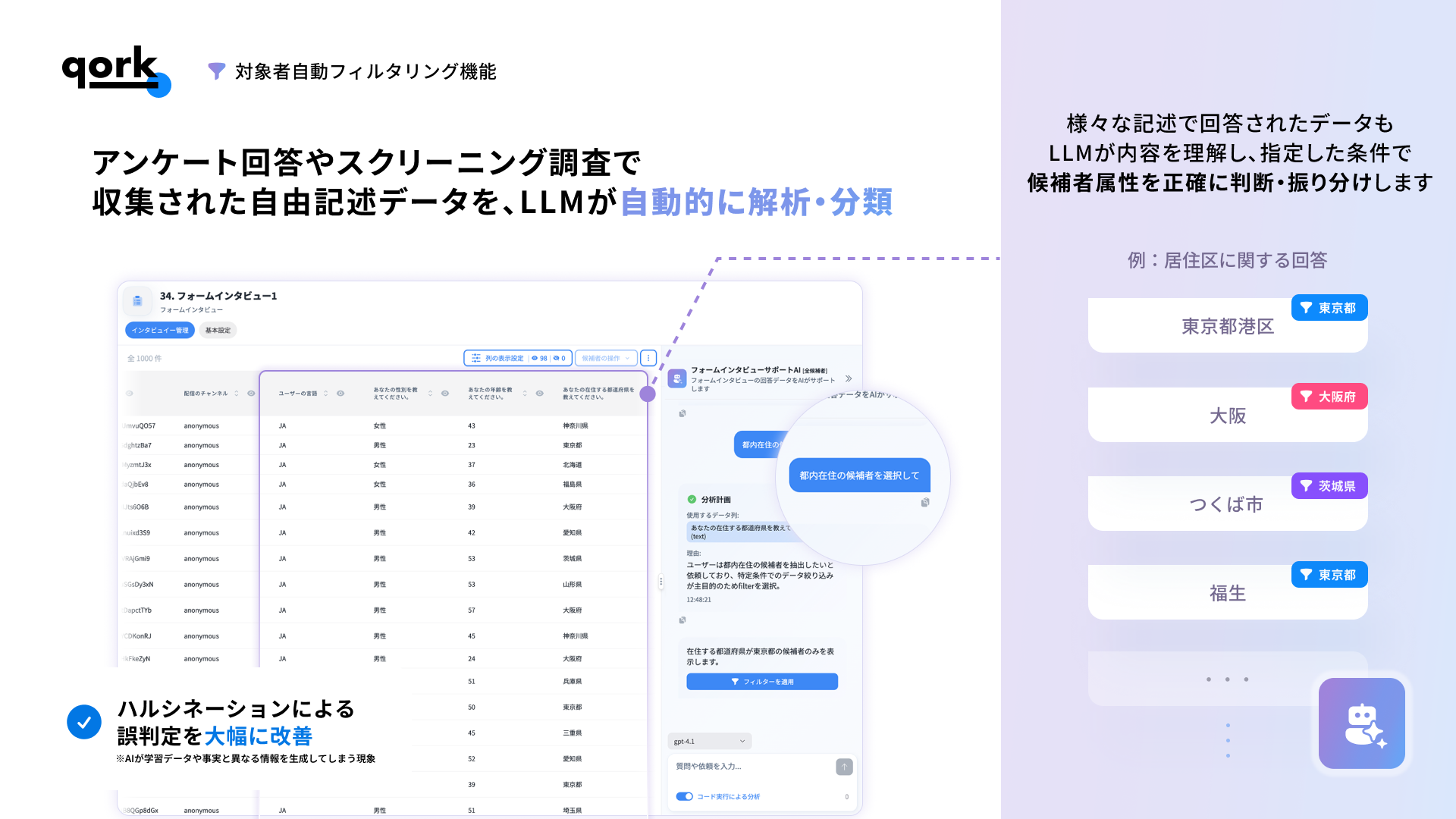
本機能は、アンケート回答やスクリーニング調査で収集された自由記述データを、LLMが自動的に解析・分類し、調査目的に適した候補者を瞬時に抽出する機能です。
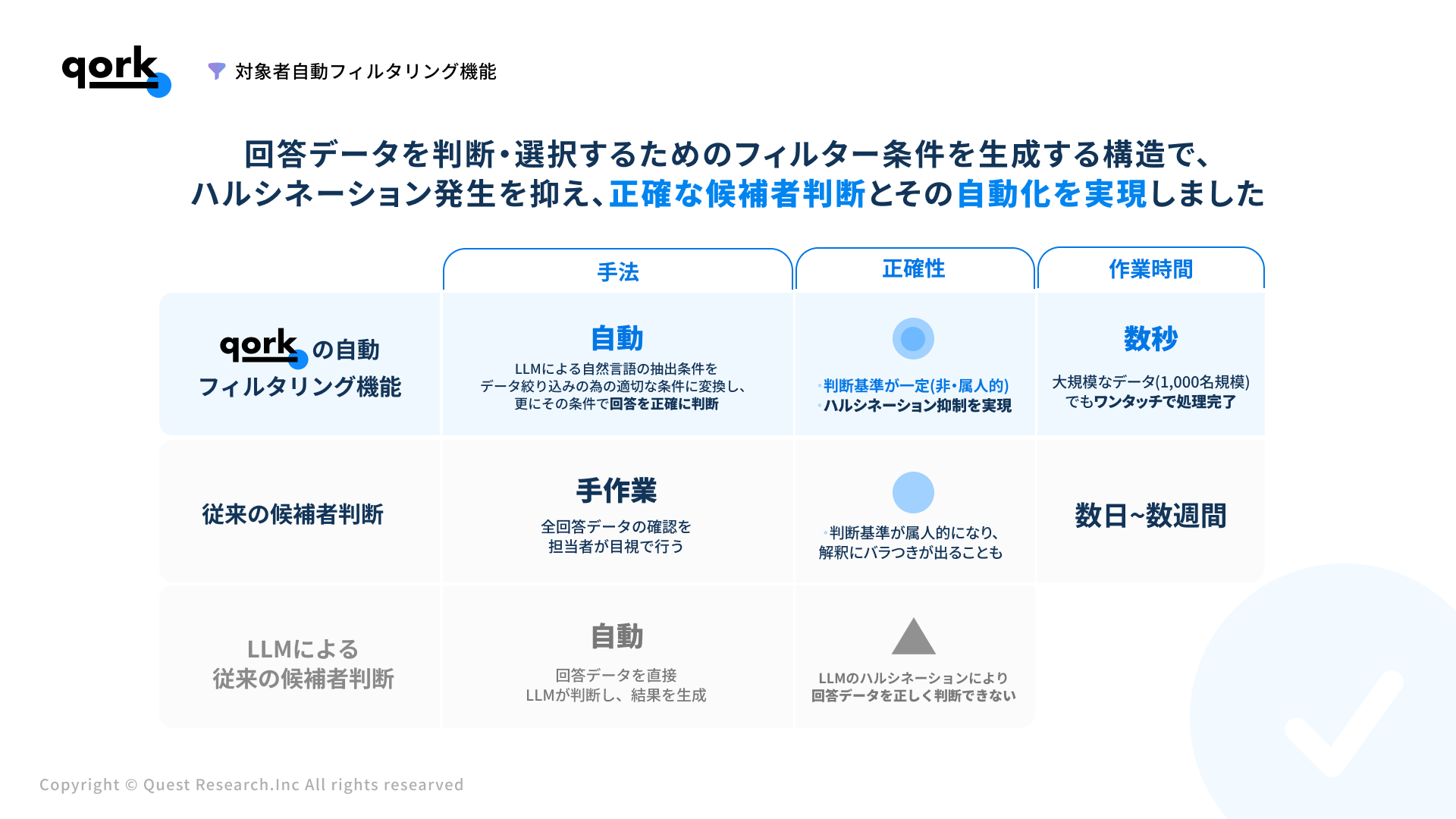
技術的特徴として、LLMに直接候補者を選択させるのではなく、自然言語の抽出条件から適切なフィルター条件を自動で生成させます。この独自のアプローチにより、一般的なLLMを用いた手法の課題であった、AIが事実と異なる情報を生成してしまう現象「ハルシネーション」による誤判定を大幅に削減し、高いリコール(漏れの少なさ)とプレシジョン(精度の高さ)の両立を実現しました。
例えば、年収に関する質問に対して「400~600万」「年収は大体500万くらい」「月給35万×12ヶ月+ボーナス」など、様々な形式で回答されたデータでも、LLMが内容を理解し、指定した条件に適合する候補者を正確に抽出します。
■背景:インタビュー候補者抽出における従来からの課題
従来の課題
これまで、インタビュー候補者の抽出作業では以下のような課題がありました:
- 手作業による全回答データの確認:「あなたの年収は」という質問に対して「400~600万」「500万程度」「年収500」など、回答者によって記載形式が異なるため、調査担当者が全ての回答内容を目視で確認し、手作業で分類する必要がありました。
- 地域指定の複雑さ:「関東圏と中国地方の人を抽出したい」という一見シンプルな要望に対し、「東京」「神奈川県横浜市」「広島」「岡山県」など、多様な記載形式の居住地データから該当する都県を手動で特定し、複雑なフィルター条件を設定する必要がありました。
- 複雑なフィルター条件の設定:自由記述の内容を数値化・分類するために、複雑な条件分岐を手動で設定する必要がありました。
- 属人的な判断基準: 担当者によって解釈が異なり、抽出結果にばらつきが生じるリスクがありました。
- 大量データ処理の限界:候補者数が増えるほど作業時間が膨大になり、迅速な調査実施の妨げとなっていました。
- LLM直接選択手法の限界:LLMに直接候補者選択を委ねる手法では、ハルシネーションにより「該当しない候補者を選んでしまう」「該当する候補者を見落とす」といった精度問題が深刻で、実用化の大きな障壁となっていました。
■新機能による課題解決
本機能では、これらすべての課題を独自の技術アプローチにより解決します:
【ハルシネーション問題の根本解決】
- フィルター条件生成アプローチの採用:LLMに候補者を直接選択させるのではなく、自然言語の抽出条件を適切なデータベースフィルター条件に変換させることで、ハルシネーションの発生を構造的に防止。
- 高精度な抽出の実現:リコール(見落としの少なさ)とプレシジョン(誤抽出の少なさ)を両立し、従来のLLMベースフィルタリングで課題となっていた精度問題を解決。
【その他の自動化機能】
- 自動内容理解:「400~600万」「月収40万程度」「年俸500万円」など、多様な記述形式を自動的に理解・統一化
- 地域概念の自動判定:「関東圏の人」という条件を設定するだけで、「東京」「神奈川県横浜市」「埼玉」「千葉県船橋市」「茨城県つくば市」「栃木」「群馬県高崎市」などの多様な記載から該当者を自動抽出
- 瞬時の条件適用: 「年収500万円以上の候補者」「中国地方在住者」といった抽出条件を自然言語で設定するだけで、該当者を瞬時に特定
- 一貫した判断基準: LLMによる客観的な判断により、担当者による解釈の違いを排除
- 大規模データ対応: 最大1000名規模のデータでも数秒で処理完了
■本機能がもたらす革新的な価値
正確かつ迅速なインタビュー候補者の抽出は、定性調査におけるオペレーション効率化と分析精度向上の基盤となる重要な作業です。本機能により実現される価値は以下の通りです:
【オペレーション面での価値】
- 作業時間の大幅短縮:従来数時間~数日かかっていた候補者抽出作業が数分で完了
- 人的リソースの最適化:単純作業からリサーチャーを解放し、より本質的な調査設計や分析に集中可能。
- スケーラビリティの向上:大規模調査でも迅速な候補者抽出が可能。
【分析面での価値】
- 課題を解決した高精度抽出による分析品質の向上:フィルター条件生成アプローチによりハルシネーション問題を根本解決し、見落としや誤分類を大幅に削減。
- 条件設定の柔軟性:複雑な組み合わせ条件も自然言語で指定可能。
- 再現性の確保:同一条件での抽出結果が常に一貫して再現可能。
- 大規模処理対応: 最大1000名規模の候補者プールでも安定した高精度抽出を実現
■具体的な活用例
本機能は以下のような様々な調査シーンで威力を発揮します:
- 地域別調査:「関東圏」「関西圏」「九州地方」など地域概念での抽出や、「東京都23区内」「大阪市内」「地方都市」などの詳細な地域指定。
- 職業・業界調査:「IT関係の仕事」「コンサル系」「メーカー勤務」など曖昧な記述から正確な分類
- 年収・年齢調査: 「30代前半」「年収400万台」「20代後半」などの幅のある表現を数値化
- ライフスタイル調査:「子育て中」「一人暮らし」「実家暮らし」などの生活状況を体系的に分類
- 商品・サービス利用状況:「たまに使う」「月1~2回」「週末だけ」などの頻度表現を統一化
■今後の展開
Quest Researchでは、本機能を通じてqorkの「リサーチャーのためのインタビューサービス」としての価値をさらに向上させてまいります。候補者抽出の自動化により創出された時間を、より本質的な調査設計や深い分析に充てることで、クライアント企業様により価値の高いインサイトを提供してまいります。また、海外調査における多言語データの自動分類や、より複雑な抽出条件への対応など、LLM技術を活用したさらなる機能拡張も検討してまいります。
■qorkについて
より詳しい情報をご希望の方は、下記よりお気軽にお問い合わせください。
▼サービスに関するお問い合わせ
https://share.hsforms.com/1zVhjca8iTUWv95Y_UU6brA59gws
▼qork公式サイト
https://qork.jp/product